Kaboom: Return of Kaboom
My Work
- Neural network (NN) trained for pathfinding of enemy NPC airplanes
- Interactions between the player and enemy NPC airplanes
- Patrol behaviour for enemy NPC airplanes
You can check out our itch.io page and download/play the game using the following link: Kaboom: Return of Kaboom. This project was made in Unreal Engine 5.4, where we only used blueprints.
Enemy NPC airplane interaction with the player
- NPC airplanes can chase and circle the player.
- They will periodically target and shoot the player.
- If the player flies away and "escapes" or is sighted by a radar, it will cause the NPC airplanes to patrol the last known player position for a duration.
Neural Network pathfinding of enemy NPC airplanes
The goal of my neural network is for agents (enemy NPC airplanes) to move/follow a target, which can be the current player position, the last known player position or their base. To accomplish this we have to think about what data to give to the neural network (input) and what data we want to get from the neural network (output).
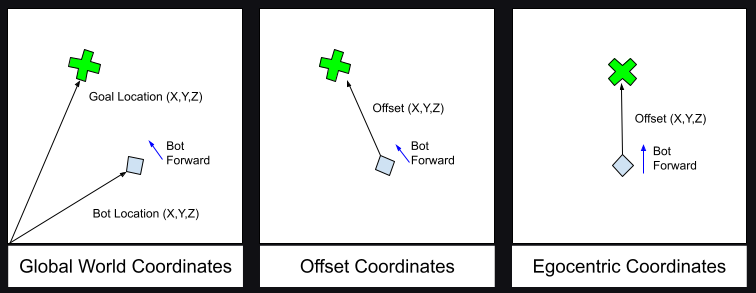
A neural network requires input to work, you can think of this input as sight. We see things from our point of view, similarly we can make the NN agents see the world from their position in the world. Translating this input to the agent's relative world positions will improve the behaviour and decrease the complexitiy of the NN. We can accomplish this by translating the target world coordinates to egocentric coordinates, before passing it to the NN.
My neural network uses two outputs: an angle and a throttle. The angle is used to steer the airplanes, allowing them to turn and move towards their target. And the throttle is used to determine the speed of the airplanes. These outputs are clamped between minimum and maximum values, because airplanes are unable hang still in the air, nor can they move faster then their limit or take a 90° turn. Something important to note is that the input is an egocentric coordinate, it does not matter to the neural network what this coordinate represents. That is for us to determine, which makes this a very robust pathfinding neural network that can be used for the airplanes we use in our game.